
In last post about analyzing open source development I mentioned that this one would be about massaging people information to have unique identities for all the project contributors.
But before that, I would like to explore something different. How to get data from multiple repositories? What happens when I want data from a whole GitHub organization’s or user’s repositories?
The obvious answer would be:
1. Let’s get the list of repositories:
import requests
def github_git_repositories(orgName):
query = "org:{}".format(orgName)
page = 1
repos = []
r = requests.get('https://api.github.com/search/repositories?q={}&page={}'.format(query, page))
items = r.json()['items']
while len(items) > 0:
for item in items:
repos.append(item['clone_url'])
page += 1
r = requests.get('https://api.github.com/search/repositories?q={}&page={}'.format(query, page))
items = r.json()['items']
return repos
2. And now, for each repository, run the code seen in previous post to get a dataframe for each one in list and concat them with:
df = pd.concat(dataframes)
For organizations or users with a few repositories, it would work. But for those with hundreds of repositories, how long would it take to go one by one fetching and extracting info?
Would there be a fastest approach? Let’s play with threads and queues…
Entering the danger zone
Threads are quite complicated, and I am sure there are better approaches than the one in this post. The idea is to show a simple a way to run several git data downloads in parallel.
First of all, let’s put the gathering data code in a function, that given a git URI, it returns a dataframe with some basic information:
from perceval.backends.core.git import Git
import numpy as np
import pandas as pd
def git_raw_data(gitURI):
git_repo = gitURI.split('/')[-1]
data_repository = Git(uri=gitURI, gitpath='/tmp/{}'.format(git_repo))
df = pd.DataFrame()
for commit in data_repository.fetch():
if 'message' not in commit['data'].keys():
commit['data']['message'] = ''
for file in commit['data']['files']:
df = df.append({'repository': commit['origin'].split('/')[-1].split('.git')[0],
'username': commit['data']['Author'],
'commit': commit['data']['commit'],
'date': commit['data']['AuthorDate'],
'filepath': file['file'],
'added': int(file['added']) if 'added' in file.keys() and file['added']!='-' else 0,
'removed': int(file['removed']) if 'removed' in file.keys() and file['removed']!='-' else 0},
ignore_index=True)
df['date'] = pd.to_datetime(df['date'])
return df
And now, let’s define a function that given a set of repositories, create a thread for each one’s data retrieval, and get a set of dataframes that are joined with pd.concat():
from threading import Thread
from queue import Queue
def git_dataframe(repositories):
dataframes = []
threads = []
que = Queue()
for repo in repositories:
t = Thread(target=lambda q, arg1: q.put(git_raw_data(arg1)), args=(que, repo))
threads.append(t)
t.start()
for t in threads:
t.join()
while not que.empty():
result = que.get()
dataframes.append(result)
dataframe = pd.concat(dataframes)
return dataframe
Part of the magic is done by a queue (que = Queue()) that is used to store the data retrieved in each thread:
t = Thread(target=lambda q, arg1: q.put(git_raw_data(arg1)), args=(que, repo))
Let’s run the code we have:
In[]: repositories = github_git_repositories('grimoirelab')
repositories
Out[]:
['https://github.com/grimoirelab/perceval.git',
'https://github.com/grimoirelab/GrimoireELK.git',
'https://github.com/grimoirelab/sortinghat.git',
'https://github.com/grimoirelab/use_cases.git',
'https://github.com/grimoirelab/arthur.git',
'https://github.com/grimoirelab/panels.git',
'https://github.com/grimoirelab/mordred.git',
'https://github.com/grimoirelab/grimoirelab.github.io.git',
'https://github.com/grimoirelab/reports.git',
'https://github.com/grimoirelab/grimoirelab-toolkit.git',
'https://github.com/grimoirelab/perceval-opnfv.git',
'https://github.com/grimoirelab/perceval-mozilla.git',
'https://github.com/grimoirelab/perceval-puppet.git',
'https://github.com/grimoirelab/grimoirelab.git']
In[]: grimoirelab_git_raw_df = git_dataframe(repositories)
In[]: grimoirelab_git_raw_df.info()
Int64Index: 13112 entries, 0 to 4460
Data columns (total 7 columns):
added 13112 non-null float64
commit 13112 non-null object
date 13112 non-null datetime64[ns]
filepath 13112 non-null object
removed 13112 non-null float64
repository 13112 non-null object
username 13112 non-null object
dtypes: datetime64[ns](1), float64(2), object(4)
memory usage: 819.5+ KB
Cool, now we have a big dataframe with data for all the files edited through commits in a whole organization
Time to enrich the data
Before going a bit further, let’s enrich the data we have. We currently have:
username, as the whole name and email used by the commit author. It would be more useful to have it as: name, email, email domain (for example)filepath, as the whole file path to the file edited. It would be interesting to have it as: file name, file extensiondate, as the whole commit date information. It might be interesting to have also: the hour of the commit and the day of the week
How to do that? It’s a pandas dataframe so we could have an enrich function like this:
def enrich_git_data(df):
df['name'] = df['username'].map(lambda uname: uname.split('<')[0][:-1])
df['email'] = df['username'].map(lambda uname: uname.split('<')[1].split('>')[0])
df['email_domain'] = df['username'].map(lambda uname: uname.split('@')[-1][:-1])
df['isoweekday'] = df['date'].map(lambda d: d.isoweekday())
df['hour'] = df['date'].map(lambda d: d.hour)
df['file_name'] = df['filepath'].map(lambda file: file.split('/')[-1])
df['file_ext'] = df['file_name'].map(lambda file: file.split('.')[-1])
return df
And let’s apply it to previous dataframe:
In[]: grimoirelab_git_data = enrich_git_data(grimoirelab_git_raw_df)
In[]: grimoirelab_git_data.info()
Int64Index: 13112 entries, 0 to 4460
Data columns (total 14 columns):
added 13112 non-null float64
commit 13112 non-null object
date 13112 non-null datetime64[ns]
filepath 13112 non-null object
removed 13112 non-null float64
repository 13112 non-null object
username 13112 non-null object
name 13112 non-null object
email 13112 non-null object
email_domain 13112 non-null object
isoweekday 13112 non-null int64
hour 13112 non-null int64
file_name 13112 non-null object
file_ext 13112 non-null object
dtypes: datetime64[ns](1), float64(2), int64(2), object(9)
memory usage: 1.5+ MB
Great! Now we have some columns to play with.
What is the average hour we do commits in GrimoireLab?
In[]: grimoirelab_git_data.groupby('commit')['isoweekday'].mean().median()
Out[]: 3.0
In[]: grimoirelab_git_data.groupby('commit')['hour'].mean().median()
Out[]: 13.0
So, it seems that we usually commit on Wednesday around 1pm.. Just on time for lunch!
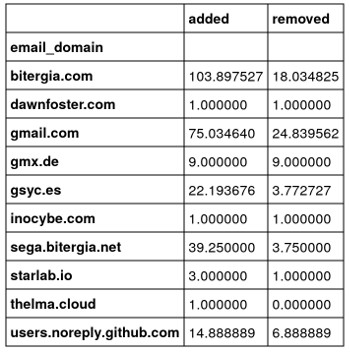
Which email domains have contributed to GrimoireLab? Which is the average lines of code added and removed by each one?
In[]: grimoirelab_git_data.groupby('email_domain')['added', 'removed'].mean()
What's next
And that's all by now. Christmas time is coming, so next post will be in January, and it will cover the promised contributors information massaging part.
Meanwhile, enjoy these days and let's get back in 2018!