During one of the episodes from “The Web is The Platform” podcast (in Spanish), there was a question about how much javascript frameworks and libraries developers are involved in Web related standards development? And I immediately thought that it could be answered with cauldron.io. Let’s try …
First step: let’s frame the question
The general question could be vague and too general: “how much javascript frameworks and libraries developers are involved in Web related standards development?” From a quick read, you could start wondering: Who are the javascript developers? What javascript frameworks and libraries? Which Web related standards?
My recommendation for this type of questions is to start with simple things, easy to measure to see if we could get a significant answer. For example:
“How many developers that have written code for top javascript frameworks and libraries , like angular, react, and vue have written code in HTML standard or ECMAScript specification?”
Second step: let’s go for the data
From the question is clear that we must gather data from angular, react, vue, HTML standard, and ECMAScript specification repositories.
In cauldron.io, add a new project, give it a name, and start adding GitHub repositories as data sources:

Third step: Play with the data
Once the data is gathered, cauldron.io provides some basic charts for the aggregated data source repositories. Of course, you can publicly share them and use them as initial basic information. Cauldron team is working on ideas to provide meaningful metrics in these tabs. If you have any idea or request, feel free to comment it in the Cauldron Community feedback section.
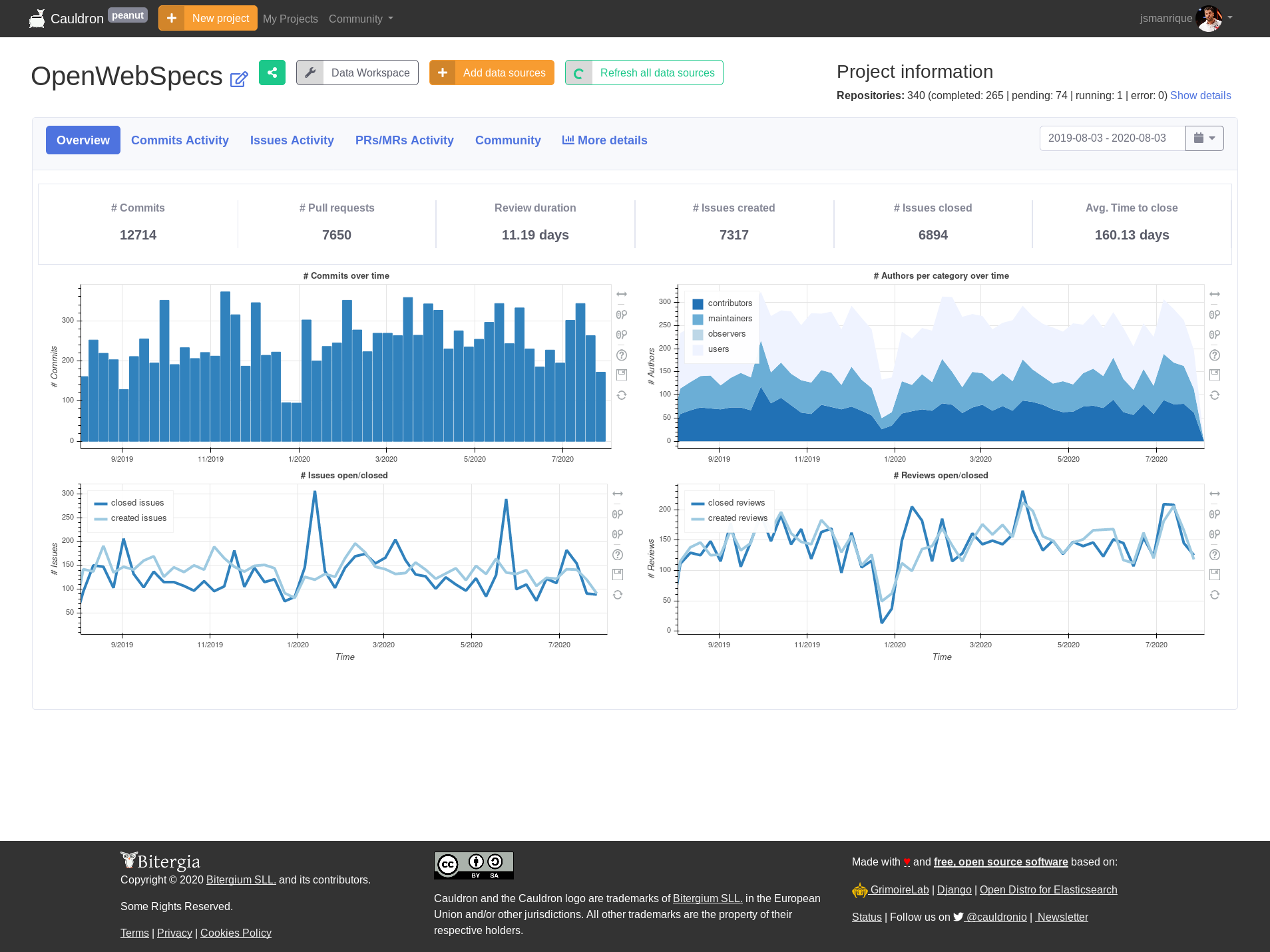
But the question we have is not answered by these metrics and charts. How could I get the answer I am looking for?
Easy! In the top of the page there is a Data Workspace button that gives you to a dedicated Kibana instance based on Open Distro open source project.
With it, you have access to the data processed by GrimoireLab, the core analytics tool in cauldron.io, to produce the metrics you’ve seen in the general overview. You can read Kibana documentation created by Elastic to learn more about available visualizations and how to use them. Let’s create a metrics visualization for the authors that have written code in such repositories:
- Select “Visualize” in the side bar menu, and click on “Create a new visualization option”
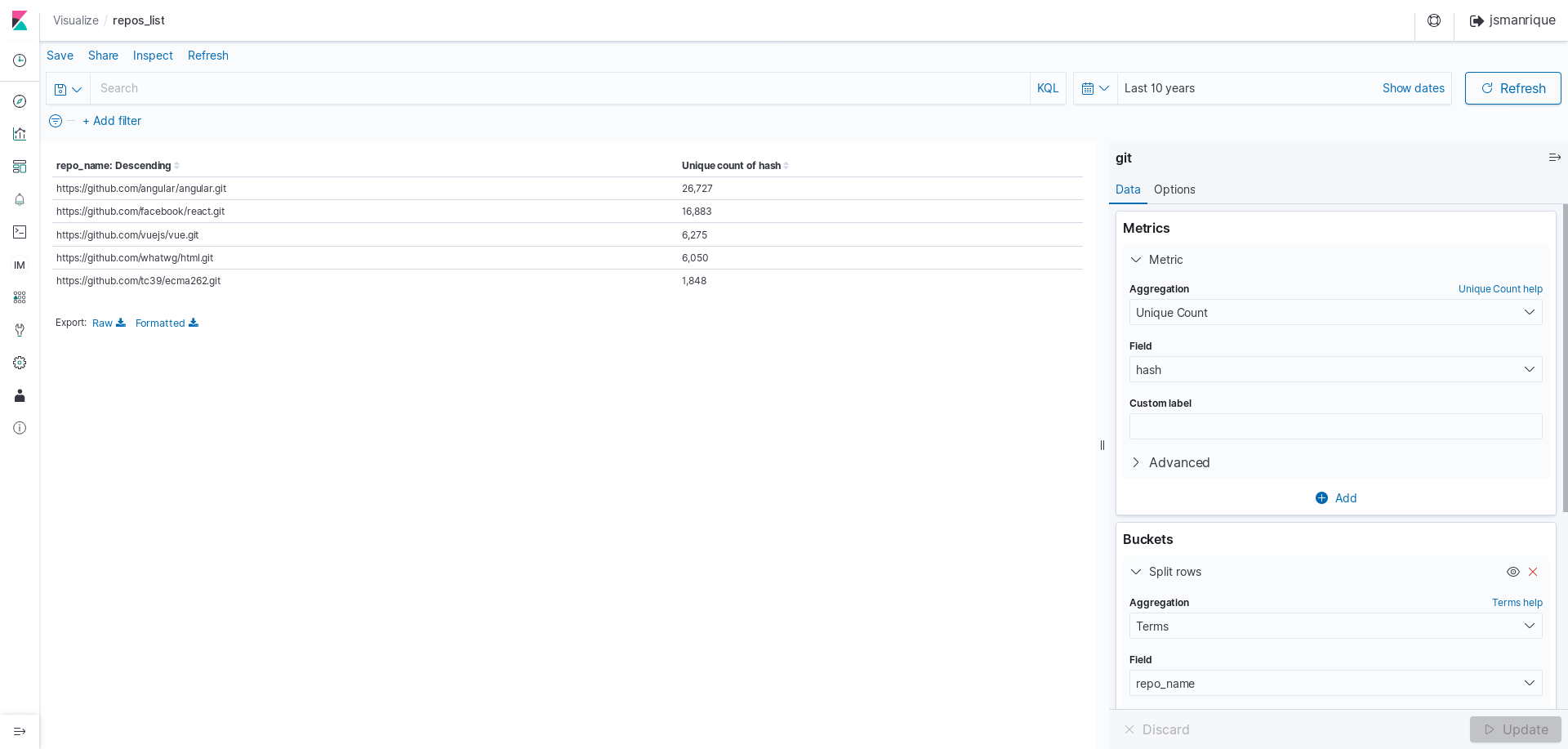
- Select “Metric”, and choose “git” as source. (It is one on the indexes created by GrimoireLab for cauldron.io).
- The metric number shows the count of items in the index (commits), so we need to change the metrics to the “unique_count” of “author_uuid”. What is this “author_uuid”? Cauldron doesn’t store any personal data information (like author’s name and email). Of course, they are “public”, but the team is concern about how people could use that data, and they take people’s privacy seriously. So, such information is anonymized, and a unique count (“unique_count”) of such generated unique ids (“author_uuid”) will give you the number of unique
"name email"information used by the commit’s author. - If you want, adjust time frame to a significant amount of time. 1 year is the default one.
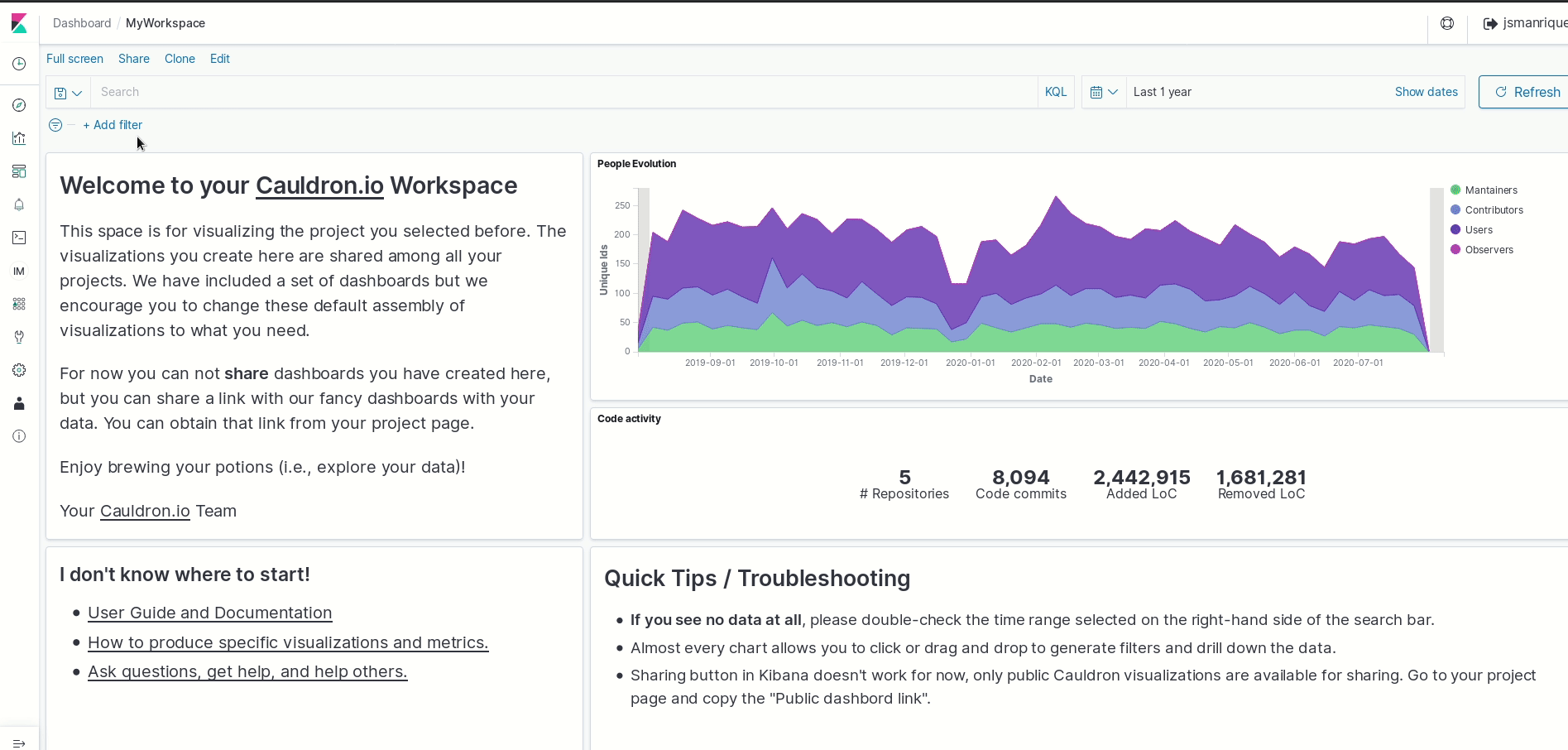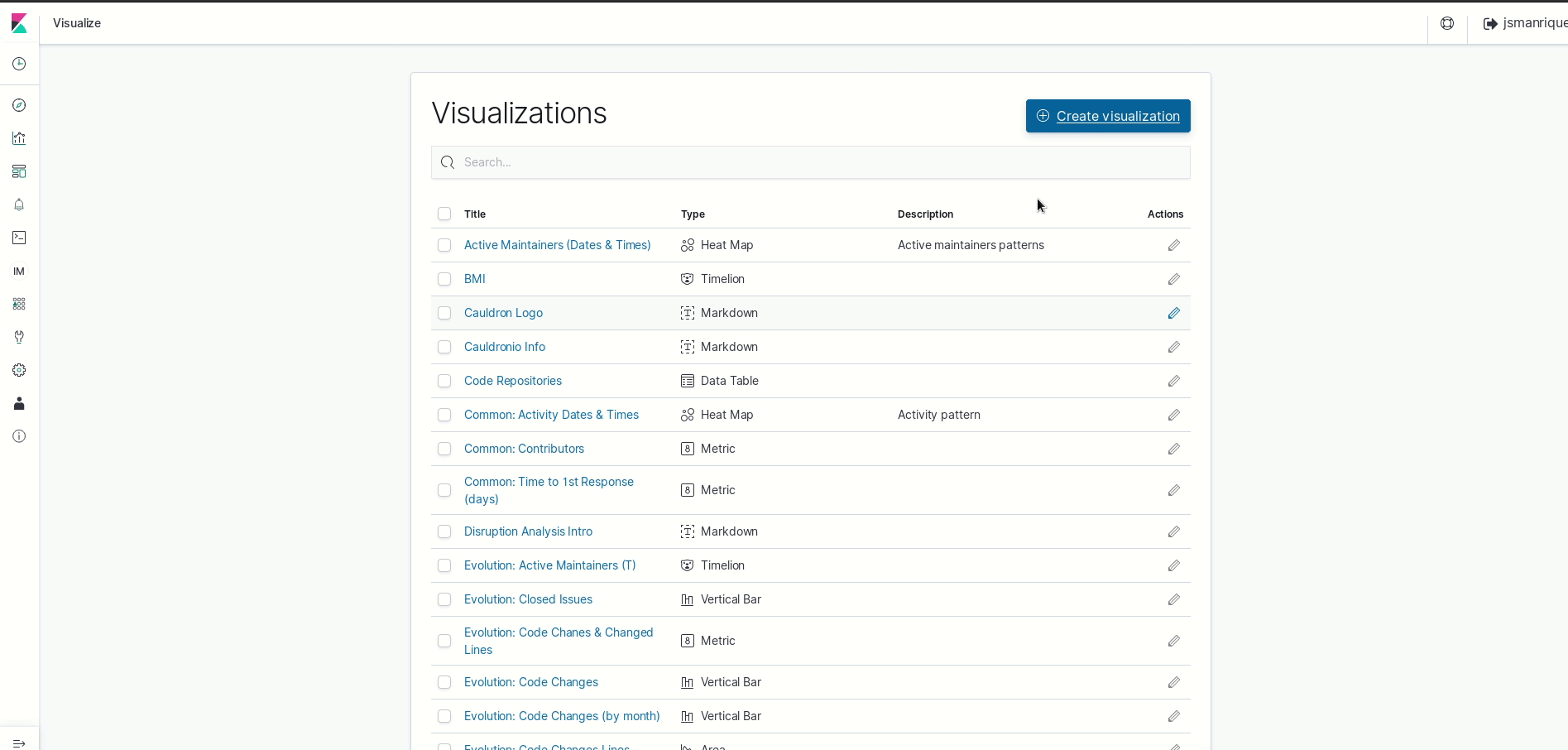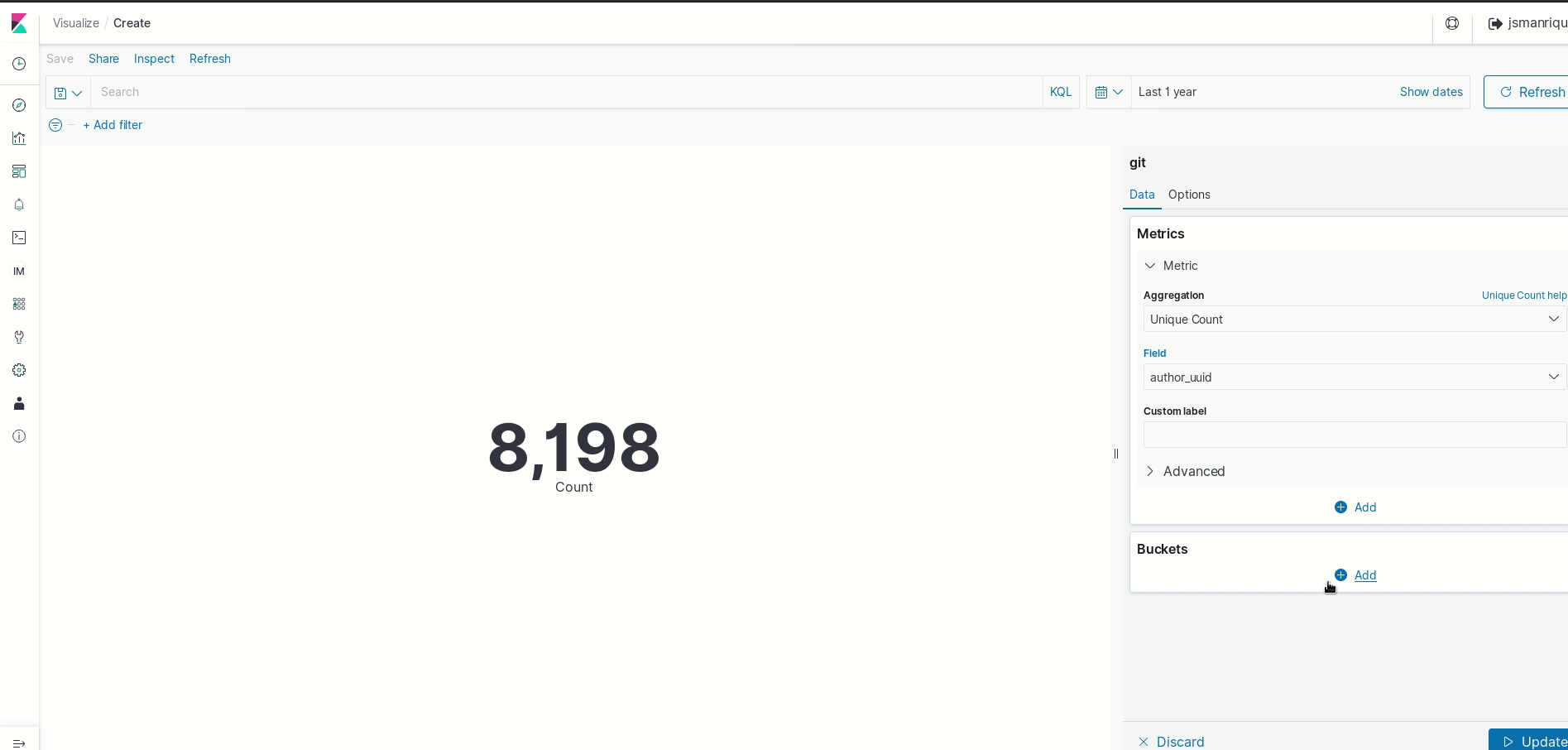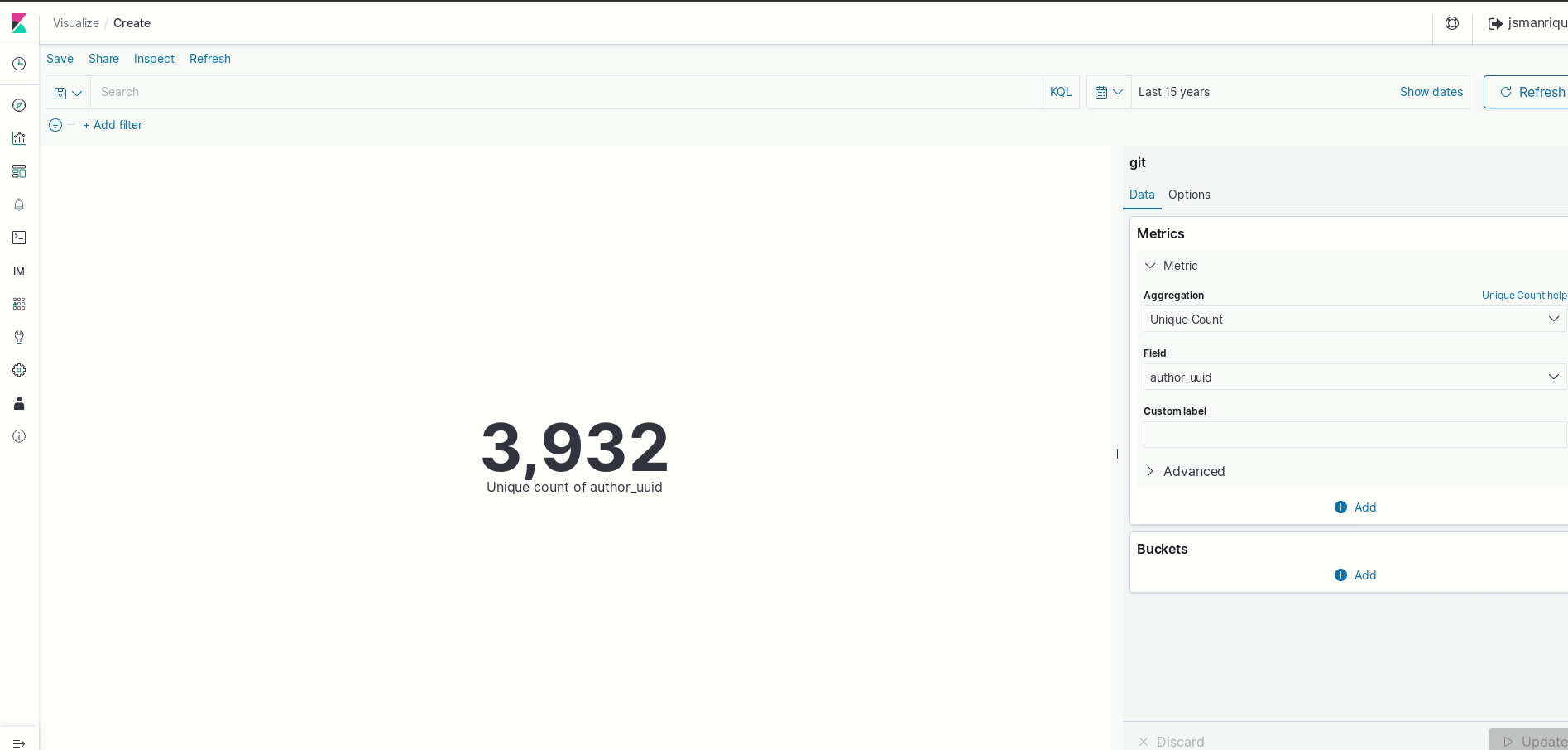
Ok, we already have an approximation of the number of people that has written code for the repositories we are analyzing. Now, to answer our question we need to filter the data. For example:
- Create a filter to check authors in “repo_name” associated to HTML standard
- Create another filter to check authors in one of the “repo_name” associated to angular, vue or react
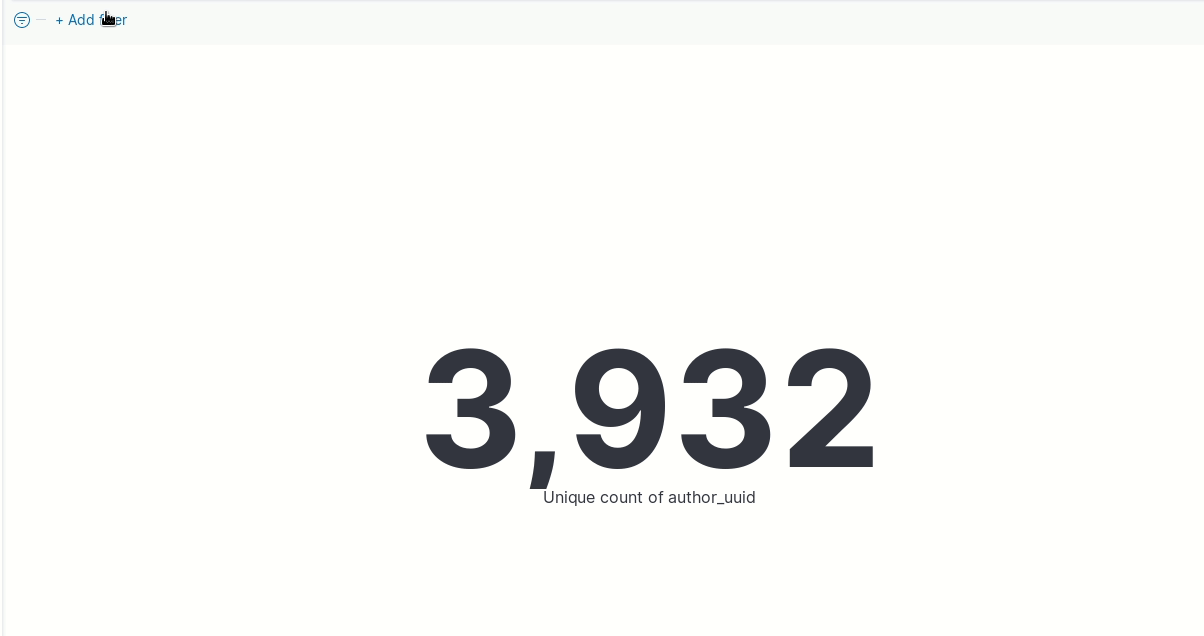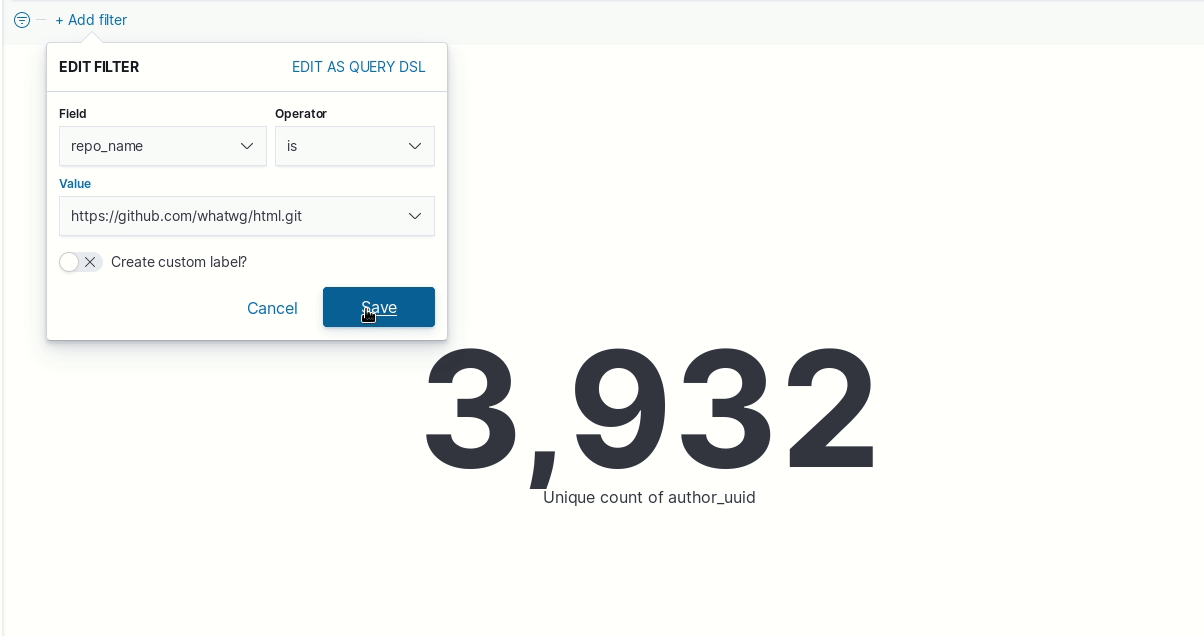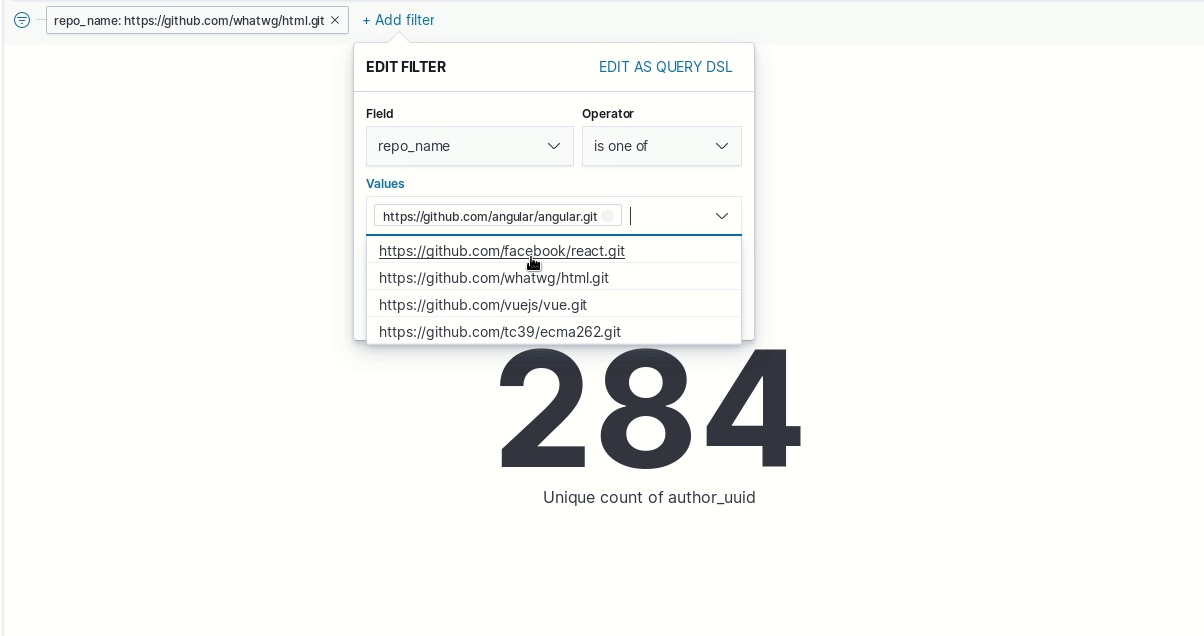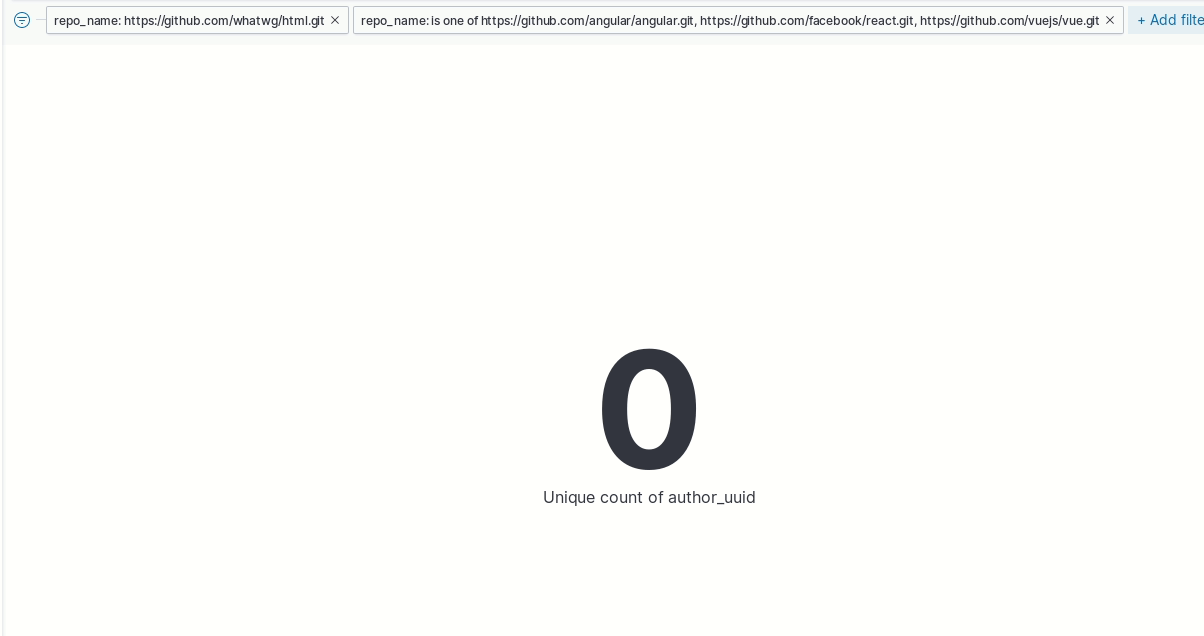
That’s it, you’ve got your answer. Right? The answer is no, that’s not the right way to get the answer!
Understanding the data you are playing with
We are using the git index that contains information about all the commits in the selected repositories. You can see how it looks like in the Discover option from the the side bar menu, and if you select git index.
Basically, it contains a set of items with several fields that includes "repo_name" as one of them. In the previous visualization, what we have done is:
- Count the number of unique
"author_uuid"values that appear in such set of commits - Filter those commits with a certain
"repo_name" - Filter again using a different
"repo_name"will give always zero because one commit cannot be in several repositories at the same time (if there are not forks)
This is a usual misunderstanding of how Kibana works. For me, it was logical to think that I was listing or counting the unique "author_uuid" values, so filtering the list of "author_uuid" by 2 different "repo_name" was obvious to get only the list or number of "author_uuid" in both repositories. The matter is that filters are applied to the items in the index, not the things I am visualizing.
How could I get the answer ?
There might be better ways, but I’ve followed these steps:
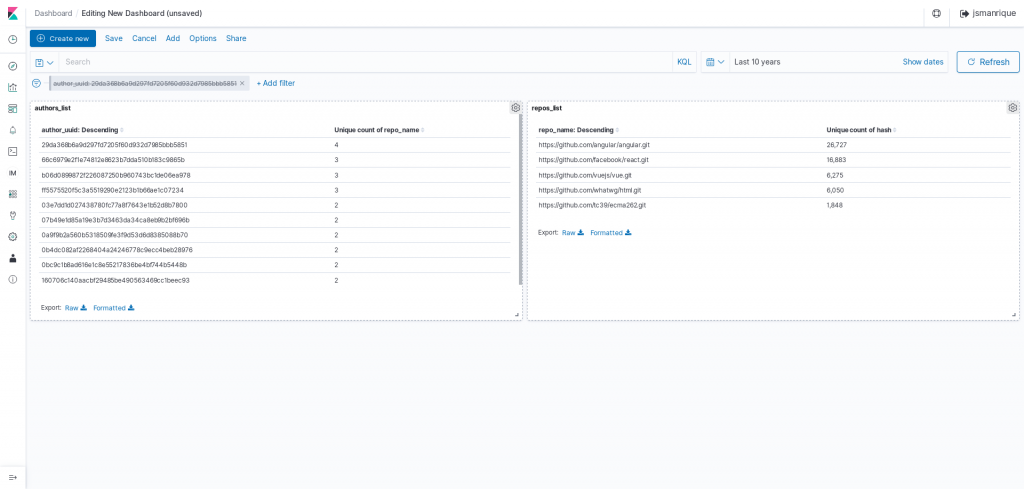
First, I’ve created a table visualization that list "author_uuid" and the number of repositories they have commited code to.

I have saved it as "authors_list". Then, I have created a similar visualization to get the list of repositories.
I have saved it as "repos_list".
After that, I have gone to “Dashboard” option in the side bar menu, and selected to create a new dashboard. I’ve added both visualizations to it:
And now, we can start to play!
Getting answers
It seems there is one single “author” that has contributed to 4 different repositories during the last 10 years. If we click on it, then the list of repositories gets filtered, and voilà! She has committed to react (3 commits), angular, ecma262, and html (1 commit to each one):

We could check the rest of people that has participated in more than 1 repository to see if there is anyone else that has participated in a one of the specs and one of the javascript frameworks. Here are some things I’ve discovered playing with some filters:
- There is one person that has contributed to react (34 commits), vue (12 commits), and angular (6 commits)
- There is one person that has contributed to ecma262 (114 commits), react (2 commits), and html spec (1 commit)
- There are several people that have contributed to 2 of the 3 javascript frameworks
- There are people that has contributed to ecma262 and html specs (probably around 400)
Disclaimer and next actions
If you find any glitch in the data, or the way it has been produced, feel free to comment to help me to improve it.
If you find this interesting and you would like to perform your own analysis, give cauldron.io a try to answer your own questions. If you have any feedback and comments, please, let us know about them in Cauldron community.
And of course, cauldron.io is 100% free, open source software, so feel free to submit any issue and request to the project! It’s built on Django, GrimoireLab, Open Distro for Elasticsearch, and Bokeh as significant dependencies.